前言:
unsloth.ai动态量化模型:https://unsloth.ai/blog/deepseekr1-dynamic
大模型运行框架Ollama:https://ollama.com
1.基础系统硬件
内存:192GB
显卡:万丽 RTX 4090
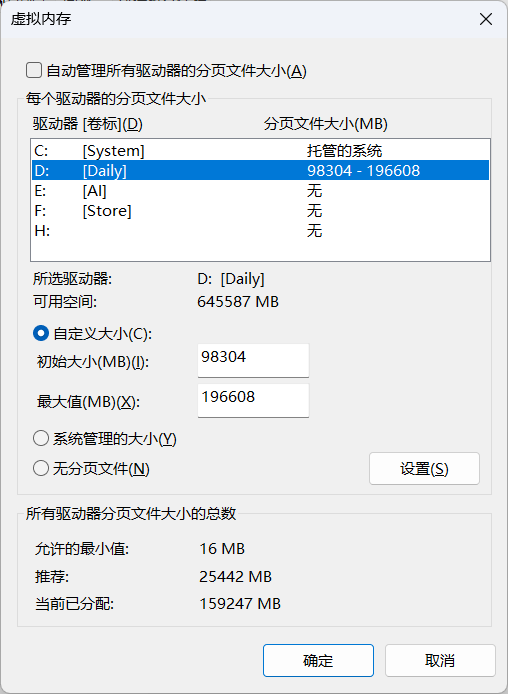
2.配置虚拟内存
最低配置内存的一般大小虚拟内存:96GB
3.下载Ollama运行包
下载:https://github.com/ollama/ollama/releases/download/v0.5.13/OllamaSetup.exe
运行安装后,直接Ollama,会常驻菜单。

4.开盖即食
运行命令下载模型:
# 模型文件:140G
ollama pull secfa/DeepSeek-R1-UD-IQ1_S:24g
# 模型文件:169GB
# 巅峰时,内存占用略小于192GB
ollama pull secfa/DeepSeek-R1-UD-IQ1_M:24g
# 模型文件:196GB
# 会爆内存, 以至于部分加载到虚拟内存上
ollama pull secfa/DeepSeek-R1-UD-IQ2_XXS:24g
# 模型文件:227GB
ollama pull secfa/DeepSeek-R1-UD-Q2_K_XL:24g
运行大模型,命令行体验:
ollama run secfa/DeepSeek-R1-UD-IQ1_M:24g --verbose
注意:如第三方API调用,需要更改监听:
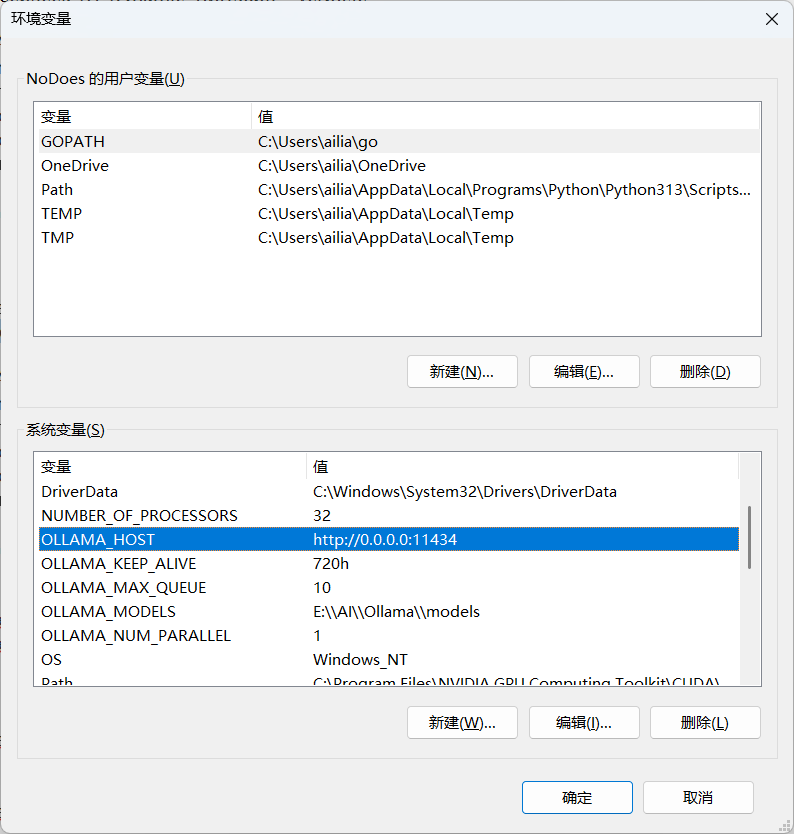
本人配置:
# API服务监听地址
OLLAMA_HOST=http://0.0.0.0:11434
# 模型在内存中保持加载的存活状态(默认五分钟)
# 永不退出加载模型
OLLAMA_KEEP_ALIVE=-1
# 排队请求的最大数量
OLLAMA_MAX_QUEUE=10
# 模型文件存储地址
OLLAMA_MODELS=E:\\AI\\Ollama\\models
# 模型并发处理数
OLLAMA_NUM_PARALLEL=1
Dify配置截图:
5.性能表现
模型:secfa/DeepSeek-R1-UD-IQ1_S:24g
# 常规153GB内存占用,20.3GB显存占用,6.4G虚拟显存
total duration: 3m52.2931578s
load duration: 24.7414ms
prompt eval count: 618 token(s)
prompt eval duration: 6.491s
prompt eval rate: 95.21 tokens/s
eval count: 429 token(s)
eval duration: 3m45.765s
eval rate: 1.90 tokens/s
模型:secfa/DeepSeek-R1-UD-IQ1_M:24g
# 常规179GB内存占用,21GB显存,6G虚拟显存
total duration: 5m19.9583399s
load duration: 53.415ms
prompt eval count: 824 token(s)
prompt eval duration: 21.859s
prompt eval rate: 37.70 tokens/s
eval count: 548 token(s)
eval duration: 4m58.031s
eval rate: 1.84 tokens/s