占用演示
代码计算如图:
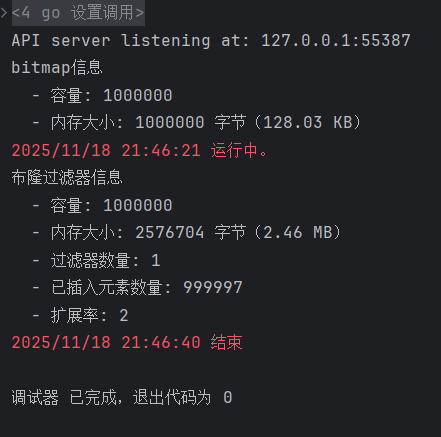
其中使用redis工具查询,占用如下:
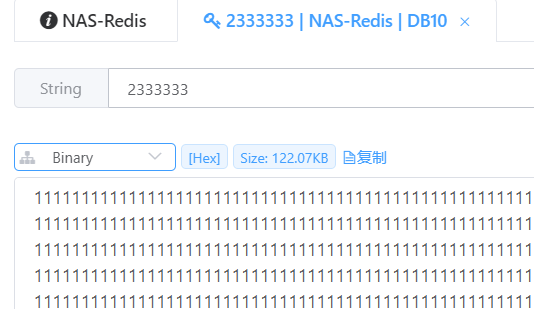
Redis封装结构
结构
redis中,所有的对象,都是基于Redis封装结构(Redis Object)展开的,其结构如下:
typedef struct redisObject {
// 数据类型 (4 bits)
unsigned type:4;
// 内部编码方式 (4 bits)
unsigned encoding:4;
// LRU 时间 (24 bits) 或 LFU 计数 (8 bits) + 访问时间 (16 bits)
unsigned lru:LRU_BITS; // 通常定义为 24 bits
// 引用计数 (32 bits)
int refcount;
// 指向实际数据存储的指针 (64-bit system: 8 bytes)
void *ptr;
} robj;RedisObject字段详解
Bitmap
基于理论的占用计算
一个 bit 来标记一个状态:
1 Byte(字节) = 8 bit(比特位)
理论字节数 = 1,000,000/8=125,0001,000,000/8=125,000 Bytes
理论 KB 数 = 125,000/1024≈122.07 KB
理论值就是 约 122 KB。
原因:
bitmap在redis中,实际还是基于string实现的,string底层数据结构SDS,结构如下:
长度 len字段:占用4字节,表示已用长度
已分配长度 alloc字段:占用4字节,表示已用长度
buf字节数组:保存实际的数据,基于redis是C语言实现,数组值最后占用一位。值为“\0”,额外占用一个字节,计算总长度时,需要减去一字节。
Bloom
已知参数:
n=1,000,000(元素数量)
p=0.0001(误判率)
布隆过滤器公式:
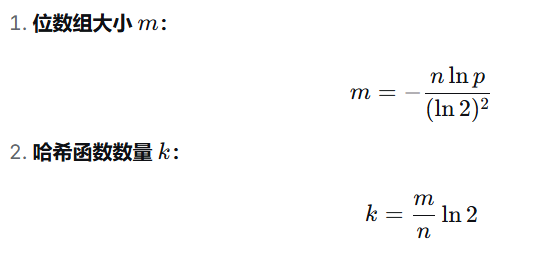 具体计算:
具体计算:

内存占用计算
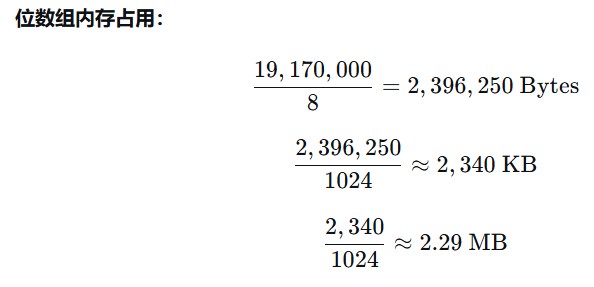
加上 Redis 数据结构开销:
Redis 的布隆过滤器(如 RedisBloom 模块)会有少量元数据开销
实际占用约 2.3 - 2.4 MB
占用对比
区别:
Bitmap 是 精确 的,但只能用于整数
布隆过滤器可以处理 任意数据类型,但存在误判
误判率越低,布隆过滤器需要的空间越大